JavaScript高级技巧
1.高级函数(操作函数的函数)
安全的类型检测
Javascript内置的类型检测机制并非完全可靠,常见的有typeof和instanceof。
以上语句要返回true,value必须是一个数组,而且还必须与Array构造函数在同个全局作用域中。在一个页面嵌入多个
frame的情况下,如果value是在另个frame中定义的数组,那么以上语句返回false。
解决上述问题的办法是:在任何值上调用Oject原生的toString()方法,都会返回一个[object NativeConstructorName]格式字符串。
Object的toString()方法不能检测非原生构造函数,因为自定义的任何构造函数都将返回[object Object]
(此方法并非完全可靠,因为Object.prototype.toString()方法也可能被修改)
作用域安全的构造函数
构造函数其实就是一个使用new操作符调用的函数。当new调用时,构造函数内用到的this对象会指向新创建的对象实例。
作用域安全的构造函数在进行任何更改前,首先确认this对象是正确类型的实例。如果不是,那么会创建新的实例并返回。
实现上述的模式后,你就锁定了可以调用构造函数的环境。如果你使用构造函数窃取模式的继承且不使用原型链,那么这个继承很可能被破坏。
(构造函数窃取模式是常见的一种实现JavaScript继承的方法,做法是在”子类“的构造函数中调用父类的构造函数以实现继承父类属性。)
Polygon构造函数是作用域安全的,但Rectangle构造函数不是。Rectangle构造函数中的this并没有得到增长,通过Polygon.call()返回的值没有用到,所以Rectangle实例中不会有sides属性。
解决方法:构造函数窃取结合使用原型链或者寄生组合
惰性载入函数
惰性载入表示函数执行的分支仅会发生一次。有两种实现惰性载入的方式:
1)在函数被调用时再处理函数
在第一次调用过程中,该函数会被覆盖为另一个按合适方式执行的函数,这样任何对原函数的调用都不用再经过执行的分支了。
以创建XHR对象的createXHR()函数为例
在这个惰性载入的createXHR()中,if语句的每一个分支都会为createXHR变量赋值,有效覆盖了原有的函数,最后一步就是调用新赋的函数,下次调用createXHR()时候,就会直接调用被分配的函数。
2)在声明函数时就指定适当的函数
第一次调用函数时不会损失性能,而在代码首次加载时会损失一点性能。
这种方法的技巧是创建一个匿名、自执行的函数,用以确定应该使用哪一个函数实现。
惰性载入函数的优点是只在执行分支代码时牺牲一点性能。
函数绑定
函数绑定要创建一个函数,可以在特定的this环境中以指定参数调用另一个函数。
结果输出:undefined。因为并没有保存handler.handleClick()的环境,所以this对象最后是指向了DOM按钮(btn)而非handler
(IE8中this指向window)。
使用闭包来修正这个问题:
在onclick事件处理程序中是用来闭包来直接调用handler.handleClick(),结果为显示Event handled。
很多JavaScript库中实现了一个可以将函数绑定到指定环境的函数,bind()。
在bind()中创建了一个闭包,闭包使用apply()调用传入的函数,并给apply()传递context对象和参数。
用法:
在ECMAScript5为所有的函数定义了一个原生的bind()方法,可以直接在函数上调用这个方法,进一步简化了操作。
支持原生bind()方法的浏览器有IE9+、Firefox4+和Chrome。
函数柯里化
与函数绑定紧密相关的主题是函数柯里化,它用于创建已经设置好了一个或多个参数的函数。
在计算机科学中,柯里化(英语:Currying),又译为卡瑞化或加里化,是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
通俗点讲,函数柯里化就是把函数完全变成「接受一个参数;返回一个值」的固定形式。
函数柯里化的基本方法和函数绑定是一样的:使用一个闭包返回一个函数。
两者区别在于,当函数被调用时,返回的函数还需要设置一些传入的参数。
curriedAdd()函数本质上是在任何情况下第一个参数为4的add()版本,尽管从技术上说curriedAdd()并非柯里化函数,但它很好地展示了其概念。
柯里化函数通常由以下步骤动态创建:调用一个函数并为它传入要柯里化的函数和必要的参数。
创建柯里化函数的通用方式:
这个函数并没有考虑到执行环境,所以调用apply时第一个参数是null。
结合函数柯里化的更复杂的bind()函数
可传入任意参数的,不传入参数时输出结果的柯里化函数:
防篡改对象
因为在JavaScript中,任何对象都可以被同一环境中运行的代码修改,开发人员很可能意外地修改别人的代码,因此ECMAScript5提出了防篡改对象。
1.不可扩展对象
默认情况下,JavaScript的所有对象都是可以扩展的,也就是说,任何时候都可以向对象中添加属性和方法。
要想改变这一行为,需要使用Object.preventExtensions(object)方法,让你不能再给对象添加属性和方法,但可以修改删除已有的属性和方法。
使用Object.isExtensible(object)方法可以确定对象是否可以扩展。
2.密封的对象
ECMAScript 5为对象定义的第二个保护级别是密封对象。密封对象不可扩展,已有属性和方法不可删除和修改。
使用Object.seal()方法密封对象:
使用Object.isSeal()方法判断对象是否被密封,因为被密封的对象不可扩展,所以用Object.isExtensible()检查密封对象也会返回false。
3.冻结的对象
最严格的防篡改级别是冻结对象。冻结对象即不可扩展,又是密封的,而且对象数据属性的[[Writable]]特性会被设置为false。如果定义[[Set]]函数,访问器属性仍然是可写的。
使用Object.freeze()方法冻结对象:
使用Object.isForzen()检测冻结对象,而使用Object.isSeal()和Object.isExtensible()检测冻结对象,分别返回true和false。
高级定时器
Javascript是运行于单线程的环境中的,而定时器仅仅只是计划代码在未来的某个时间执行。执行时机是不能保证的,因为在页面的生命周期中,不同时间可能有其他代码在控制JavaScript进程。实际上,是由浏览器负责进行排序,指派某段代码在某个时间点运行的优先级。
可将JavaScript想象成在时间线上运行,以onclick事件为例:
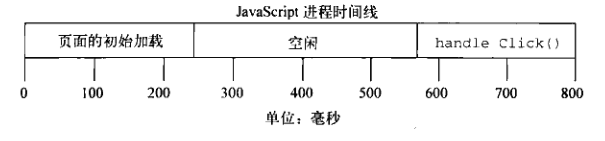
定时器对队列的工作方式是,当特定时间过去后将代码插入。注意,给队列添加代码并不意味着对它立刻执行,而只能表示它会尽快执行。
关于定时器要记住的最重要的事情是:指定的时间间隔表示何时将定时器的代码添加到队列,而不是何时实际执行代码。
重复的定时器
使用setInterval()创建的定时器确保了定时器代码规则地插入队列中。当使用setInterval()时,仅当没有该定时器的任何其他代码实例时,才将定时器代码添加到队列中。
重复定时器的规则有两个问题:
(1)某些间隔会被跳过;
(2)多个定时器的代码执行之间的间隔可能会比预期的小。
为了避免setInterval()的重复定时器的这两个缺点,可以如下模式使用链式setTimeout()调用:
这样做的好处是,在前一个定时器代码执行完之前,不会向队列插入新的定时器代码,确保不会有任何缺失的间隔,同时也能避免连续的运行。
Yielding Processes
运行于浏览器中的Javascript都被分配了一个确定数量的资源。如果代码运行超过特定的时间或者特定语句数量就不让它继续执行。
定时器就是绕开此限制的方法之一。
脚本长时间运行的问题通常由两个原因之一造成的:过长的、过深嵌套的函数调用或者是进行大量处理的循环。
对于由进行大量处理的循环导致的脚本长时间运行问题,是较容易解决的,首先确定两个问题:
1)该处理是否必须同步完成?
2)数据是否必须按顺序完成?
如果回答都为“否”,那么可以使用定时器分割这个循环:这是一种叫做数组分块的技术,小块小块地处理数组,通常每次一小块。
基本思路是:为要处理的项目创建一个队列,然后使用定时器取出下一个要处理的项目进行处理,接着再设置另一个定时器。
基本模式:
具体函数:
应注意的是,传给chunk()函数的数组是用作一个队列的,因此当处理数据时,数组中的条目也相应变化,
如果想要保持原数组不变,则应该将该数组的克隆传递给chunk(),如下所示:
数据分块的重要性在于他它可以将多个项目的处理在执行队列上分开,在每个项目处理之后,给予其他的浏览器处理机会运行,这样就可能避免长时间运行脚本的错误。
函数节流
函数节流的基本思想是指,某些代码不可以在没有间断的情况下连续重复执行。
第一次调用函数,创建一个定时器,在制定的时间间隔之后运行代码。第二次调用该函数时,它会清除前一次的定时器并设置另一个。如果前一个定时器已经执行过了,这个操作就没有意义。然而,如果前一个定时器尚未中心,其实就是将其替换为一个新的定时器。目的是只有在执行函数的请求停止了一段时间之后才执行。
基本形式:
只要代码是周期性执行的,都应该使用节流。
自定义事件
事件是一种叫做观察者的设计模式,这是一种创建松散耦合代码的技术。
观察者模式由两类对象组成:主体和观察者。主体负责发布事件,同时观察者通过订阅这些事件来观察该主体。
该模式的一个关键概念是主体并不知道观察者的任何事情,也就是说它可以独自存在并正常运作即使观察者不存在。
另一方面,观察者知道主体并能注册事件的回调函数(事件处理程序)。
事件是与DOM交互的最常见的方式,但也可以用于非DOM代码中——通过实现自定义事件。
自定义事件背后的概念是创建一个管理事件的对象,让其他对象监听这些事件。基本模式如下:
使用自定义事件有助于解耦相关对象,保持功能的隔绝。
拖放
基本概念:创建一个绝对定位的元素,使其可以用鼠标移动。这个技术源自一种叫做“鼠标拖尾”的经典网页技巧。
鼠标拖尾是一个或者多个图片在页面上跟着鼠标指针移动。
拖放示例:
离线应用与客户端存储
HTML5把离线应用作为重点,开发人员都期望web应用能够离线使用。
开发离线Web应用需要几个步骤:
- 确保应用知道设备是否能上网,以便下一步执行正确的操作。
- 应用必须能访问一定的资源(图像,Javascript,CSS等)。
- 最后,必须有一块本地空间用于保存数据,无论能否上网都不妨碍读写。
(HTML5及其相关的API让开发离线应用成为现实)
1.离线检测
为了实现检测是否离线,HTML5定义了一个navigator.onLine属性,该属性值为true表示设备能上网,值为false表示设备离线。
这个属性的关键在于浏览器要必须知道设备能否访问网络,从而返回正确的值。
在实际应用中,navigator.onLine在不同浏览器间有些小差异:
由于存在以上兼容性问题,单独使用navigator.onLine属性并不能确定网络是否连通,所以为了更好地确定网络是否可用,HTML5还定义了两个事件:online和offline。当网络从离线变为在线或者从在线变为离线时,分别触发这两个事件。这两个事件都是在window对象上触发。
2.应用缓存
HTML5的应用缓存,或者简称appcache,是专门为开发离线Web应用而设计的。Appcache就是从浏览器的缓存中分出来的一块缓存区。
要想在这个缓存中保存数据,可以使用一个描述文件(manifest file),列出要下载和缓存的资源。
描述文件示例
要将描述文件与页面关联起来,可以在<html>中的manifest属性中指定这个文件的路径,例如:
通过Javascript API能够知道缓存的行为,这个API的核心是applicationCache对象,这个对象有一个status属性,属性的值是常量,表示应用缓存的如下当前状态:
0:无缓存,即没有与页面相关的应用缓存。
1:闲置,即应用缓存未得到更新。
2:检查中,即正在下载描述文件并检查更新。
3:下载中,即应用缓存正在下载描述文件中指定的资源。
4:更新完成,即应用缓存已经更新了资源,而且所有资源都已下载完毕,可以通过swapCache()来使用了。
5:废弃,即应用缓存的描述文件已经不存在了,因此页面无法再访问应用缓存。
与缓存相关的事件:
checking:在浏览器为应用缓存查找更新时触发。
error:在检查更新或下载资源期间发生错误时触发。
noupdate:在检查描述文件发现文件无变化时触发。
downloading:在开始下载应用缓存的过程中持续不断地触发。
updateready:在页面新的应用缓存下载完毕且可以通过swapCache()使用时触发。
cached:在应用缓存完整可用时触发。
此外,通过调用update()方法可以手工干预,让应用缓存为检查更新而触发上述事件。
3.数据存储
1)Cookie
HTTP Cookie,通常直接叫做cookie,最初是在客户端用于存储会话信息的。
限制
cookie在性质上是绑定在特定的域名下的。每个域的cookie的总数是有限的,不过浏览器之间各有不同。
IE6以及更低版本限制每个域名只能20个cookie;
IE7+和Firefox最多50个;Opera最多30个;Safari和Chrome对于每个域的cookie数量限制没有硬性规定。
cookie大小也有限制,最多有4096B,为了最佳的浏览器兼容性,最好将整个cookie长度限制在4095B。
cookie的构成
名称:一个唯一确定cookie的名称(不区分大小写,必须经过URL编码)。
值:储存在cookie中的字符串值。值必须被URL编码。
域:cookie对于哪个域是有效的。所有向该域发送的请求中都会包含整个cookie信息。
路径:对于指定域中的那个路径,应该向服务器发送cookie。
失效时间:表示cookie何时应该被删除的时间戳。默认是浏览器会话结束时即将所有cookie删除,不过也可以自己设置删除时间。
安全标志:指定后,cookie只有在使用SSL连接的时候才发送到服务器。
JavaScript中的cookie
在JavaScript中处理cookie有些复杂,因为BOM的document.cookie属性不太容易处理。
通过document.cookie返回当前页面可用的所有cookie的字符串,一系列由分号隔开的名值对儿:

