BOM(浏览器对象模型)
window对象
BOM的核心对象是window,它表示浏览器的一个实例。在浏览器中,window对象有双重角色,它既是通过Javascript访问浏览器窗口的一个接口,又是ECMAScript规定的Global对象。这意味着网页中定义的任何一个对象、变量和函数,都以window作为其Global对象,因此有权访问
parseInt()等方法。
定义全局变量和在window对象上直接定义属性还是有一点差别:
全局变量不能通过delete操作符删除,而直接在window对象上定义的属性可以(IE9以下会报错)
尝试访问未声明的变量会抛出错误,但是通过查询window对象,可以知道某个可能未声明的变量是否存在。
窗口位置
使用下列代码可以跨浏览器去得窗口左边和上边的位置:
使用moveTo()和moveBy()方法有可能将窗口精确地移动到一个新位置。
这两个方法都接收两个参数,moveTo()接收的是新位置的x和y坐标值,
而moveBy()接收的是水平和垂直方向上移动的像素数。
eg:
window.moveTo(0,0); //移往屏幕左上角
window.moveBy(0,100); //将窗口向下移动100像素
这两种方法可能被浏览器禁用,且都不适用于框架,只能对window对象使用。
窗口大小
窗口的属性:innerWidth、innerHeight、outerWidth、outerHeight;
outerWidth和outerHeight返回浏览器窗口本身的尺寸。
但在Opera中,这两个属性的值表示页面视图容器的大小。
innerWidth和innerHeight则表示该容器中页面视图区的大小。
在Chrome中,innerWidth、innerHeight、outerWidth、outerHeight返回相同的值,即视口大小而非浏览器窗口大小。
此外还可以使用DOM方法取得页面可见区域的相关信息:
标准模式下:document.documentElement.clientWidth 和 document.documentElement.clientHeight
混杂模式下:document.body.clientWidth 和 document.body.clientHeight。
调整浏览器窗口大小:resizeTo()和resizeBy()
resizeTo()接收浏览器窗口的新宽度和新高度,而resizeBy()接收新窗口与原窗口的宽度和高度之差。
导航和打开窗口
window.open()方法既可以导航到一个特定的URL,也可以打开一个新窗口。
接收四个参数:要加载的URL、窗口目标、一个特性子字符串以及一个新页面是否取代浏览器历史记录中当前加载页面的布尔值。
可以调用close()方法关闭新打开的窗口,仅适用于通过window.open()打开的弹出窗口。
对于浏览器的主窗口,如果没有用户的允许是不能关
间歇调用和超时调用
javascript是单线程语言,但它允许通过设置超时值和间歇时间值来调度代码在特定的时刻执行。
前者是在指定的时间过后执行代码,而后者则是每隔指定的时间就执行一次代码。
超时调用使用window对象的setTimeout(),接收两个参数;
setTimeout()返回一个数值ID,表示超时调用。这个ID是执行代码的唯一标识符,可以通过它来取消超时调用。
间歇调用使用window对象的setInterval(),接收参数与setTimeout()相同,
也返回一个间歇调用ID,使用clearInterval()方法取消间歇调用。
超时调用setTimeout()和间歇调用setInterval()的区别是:
setTimeout()是指在隔多久后就执行代码,仅仅执行一次;
setInterval()是指每隔多久就执行代码一次,执行次数不定。
一般认为,使用超时调用来模拟间歇调用的是一种最佳模式。最好不要使用间歇调用。
在开发环境下,很少使用真正的间歇调用,原因是后一个间歇调用可能会在前一个间歇调用结束之前启动。
系统对话框
alert()、confirm()和prompt();
javascript中可以打开的对话框:查找对话框:window.find();打印对话框:window.print()
location对象
BOM最有用的对象之一,同时它也是window对象是属性,也是document对象的属性。
查询字符串参数:
位置操作:
立即打开新URL并在浏览器的历史记录中生成一条记录。
每次修改location的属性(hash除外),页面都会以新URL重新加载
而调用replace方法,可以在修改URL之后,用户不可通过单击“后退”按钮导航到前一个页面。
location.replace(“http://www.wrox.com“);
最后一个是reload()方法,作用是重新加载当前显示的页面。
navigator对象
navigator对象的属性通常是用来检测显示网页的浏览器类型
检测插件:使用plugins数组(包含的属性:name,description,filename,length)
screen对象
在javascript编程中用处不大,略过
history对象
history是window对象的属性,因此每个浏览器窗口、每个标签页乃至每个框架,都有自己的history对象与特定的window对象关联。
使用go()方法可以在用户的历史记录中任意跳转。
也可以给go()方法传递一个字符串参数,此时浏览器会跳转到历史记录中包含该字符串的第一个位置。
还有两个简写方法back()和forward()方法来代替go()的后退和前进
此外,还可以通过检查history.length是否等于0,来检测当前页面是不是用户历史记录中的第一个页面。
客户端检测
各个浏览器之间存在着差异,而客户端检测则是对此的一种补救措施,也是一种行之有效的开发策略。
最常用也最为人们广泛接受的客户端检测形式是能力检测(又称特性检测)。
能力检测的目标不是识别特定的浏览器,而是识别浏览器的能力。
基本模式:
能力检测的两个重要概念:
1.先检测达成目的的最常用的特性;
2.必须检测试剂要用到的特性
更可靠的能力检测
检测某方法是不是一个函数。
如sort:
尽量使用typeof进行能力检测
IE8及以前版本中使用typeof document.createElement返回的是“object”,IE9已修复。
在浏览器环境下测试任何对象的某个特性是否存在,要使用下面这个函数。
能力检测不是浏览器检测
在开发中应该将能力检测作为确定下一步解决方案的依据,而不是用它来判断用户使用的是什么浏览器
怪癖检测
是为了识别浏览器的特殊行为,主要是想知道浏览器存在什么缺陷。
用户代理检测
争议最大的一种客户端检测技术,通过检测用户代理字符串来确定实际使用的浏览器。
在每一次HTTP请求过程中,用户代理字符串是作为响应首部发送的,可以通过navigator.userAgent访问
在服务器端常用用户代理检测,在客户端则是被当作一种万不得已的做法。
用户代理字符串检测:
完整代码:
DOM文档对象模型
DOM描绘了一个层次化的节点树,允许开发人员添加、删除和修改页面的某一部分。
IE中DOM对象都是以COM对象的形式实现的。
文档节点是每个文档的根节点。
在HTML页面中,<html>是文档节点的唯一子节点,称之为文档元素。文档元素是文档的最外层元素,文档的其他所有元素都包含在文档元素中。每个文档只有一个文档元素。
Node类型(IE不支持)
Javascript中的所有节点类型都继承自Node类型,因此所有节点类型都共享着相同的基本属性和方法。
每个节点都有一个nodeType属性: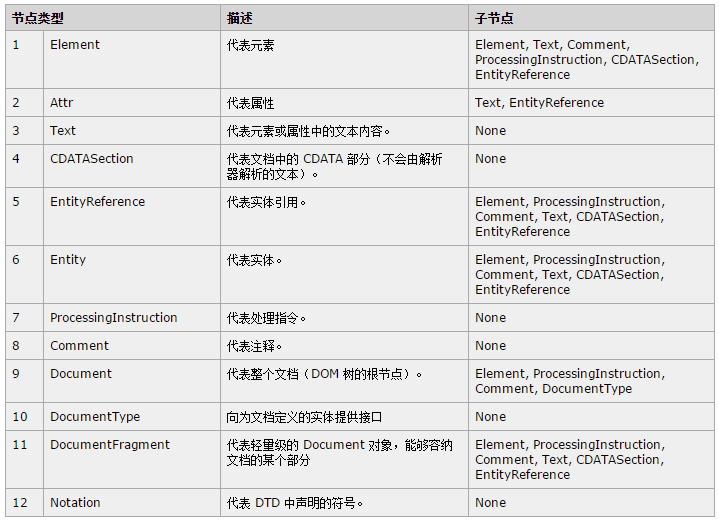
最常用:
如果节点是元素节点,则 nodeType 属性将返回 1。
如果节点是属性节点,则 nodeType 属性将返回 2。
nodeName和nodeValue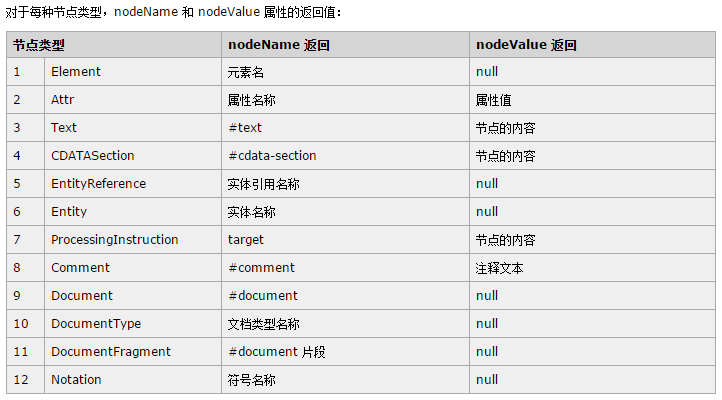
节点关系
文档中所有的节点之间都存在这样或那样的关系。
每个节点都有childNodes属性,其中保存着一个NodeList对象,这是个类数组对象(不是Array的实例),用于保存一组有序的节点。
NodeList的独特之处在于,它实际上是基于DOM结构动态执行查询的结果,因此DOM结构的变化能够自动反映在NodeList中。
将NodeList对象转换为数组:
将NodeList对象转换为数组,适用于所有浏览器中
每个节点都有一个parentNode属性,该属性指向文档树中的父节点。
兄弟节点:previousSibling和nextSibling
第一个节点和最后一个节点:firstChild和lastChild
最后还有一个属性是ownerDocument,该属性指向表示整个文档的文档节点。
操作节点
添加节点和插入节点:
appendChild()和insertBefore()
自定义实现的insertAfter()函数
接收两个参数,需要插入的节点和目标节点(在该节点后插入)
replaceNode()替换节点,接收两个参数:要插入的节点和要替换的节点。
cloneNode()克隆节点,用于创建调用这个方法的节点的一个完全相同的副本。
只接收一个布尔值参数,表示是否执行深复制。在参数为true时,执行深复制,也就是复制节点及其整个子节点树。
normalize(),唯一的作用是处理文档树中的文本节点。
当某个节点调用这个方法时,就会在该节点的后代节点中查找是否有空文本节点或连续两个文本节点,
如果有空文本节点,则删除;如果找到相邻的文本节点,则将他们合并为一个文本节点。
Document类型
在浏览器中,document对象是HTMLDocument(继承自Document类型)的一个实例,表示整个HTML页面。
此外,document对象是window对象的一个属性,因此可以将其作为全局对象来访问。
1.文档的子节点
内置的访问其子节点的快捷方式:document.documentElement属性和childNode列表。
body属性,document.body直接指向<body>元素。
通过document.doctype获取<!DOCTYPE>的引用(各个浏览器的支持不一致,因此这个属性的用处很有限)
2.文档信息
获取文档标题:document.title;
设置文档标题:document.title = “New page title”
获取URL:document.URL
获取域名:document.domain
获取来源页面的URL:document.referrer
URL和domain属性是相互关联的。
eg:URL是http://www.wrox.com/WileyCDA/,那么域名domain则是www.wrox.com
这三个属性,只有域名domain可以设置。
可以通过设置document.domain来实现js跨域通信。
浏览器对domain属性有一个限制,即如果域名一开始是”松散的“,那么不能将它再设置为”紧绷的“。
换句话说,原来的document.domain为”p2p.wrox.com“,在将document.domain设置为”wrox.com“之后,
就不能再将其设置回原来的域名”p2p.wrox.com“。
3.查找元素
document.getElementById()和document.getElementsByTagName()
如果有多个相同的id,document.getElementById()则只返回文档中第一次出现的元素。
IE7及较低版本,不区分ID大小写,并且document.getElementById()中传入的是某个元素的name属性的值,也会返回相应元素。
4.特殊集合
document.anchors,包含文档中所有带name特性的<a>元素;
document.applets,包含文档中所有的<applets>元素;
document.forms,包含文档中所有d<form>元素;
document.images,包含文档中所有d<img>元素;
document.links,包含文档中所有带href特性的<a>元素;
5.DOM一致性检测(应该在能力检测完成后进行)
DOM分为多个级别,也包含多个部分,因此检测浏览器实现了DOM的哪些部分就十分必要了。
document.implementation属性就是为此提供相应信息和功能的对象,与浏览器对DOM的实现直接对应。
DOM1级的document.implementation只有一个方法,hasFeature()。
该方法只接受两个参数:要检测的DOM功能的名称及版本号。如果浏览器支持给定名称和版本号,则返回true.
6.文档写入
document.write()、document.writeln()、document.open()、document.close()
Element类型
1.HTML元素
属性:id,title,lang,dir(语言方向),className
2.取得特性
getAttribute();
特别的,获取元素的类名是getAttribute(“class”),而不是getAttribute(“className”)。
有两类特殊的特性:style和类似onclick这样的事件处理程序
通过getAttribute()获取的style,返回的是CSS文本,而通过属性访问它则返回一个对象。
通过getAttribute()获取的onclick,返回的是相应的js代码字符串,而通过属性访问它则返回一个javascript函数。
3.设置特性
setAttribute();
如果设置的特性不存在,setAttribute()则创建该属性并设置相应的值。
4.清除特性
removeAttribute();
5.attributes属性
Element类型是使用attributes属性的唯一一个DOM节点类型。
attributes属性包含一个NameNodeMap,与NodeList类似。
NameNodeMap拥有下列方法:
getNamedItem(name):返回nodeName属性等于name的节点;
removeNamedItem(name):从列表中删除nodeName属性等于name的节点;
setNamedItem(node):向列表添加节点,以节点的nodeName属性为索引;
item(pos):返回位于数字pos位置处的节点。
6.创建元素
7.元素的子节点
元素可以有任意数目的子节点和后代节点。
获取子节点时通常要判断节点类型,进行相应的操作。
Text类型
nodeType=3,不支持子节点;
appendData(text):将text添加到节点末尾
deleteData(offset,count):从offset指定的位置开始删除count个字符
insertData(offset,text):从offset指定位置插入text
replaceData(offset,count,text):用text替换从offset指定的位置开始到offset+count为止处的文本
splitData(offset):从offset指定的位置将当前文本节点分成两个文本节点。
substringData(offset,count):提取从offset指定的位置开始到offset+count为止处的字符串空格和换行也算一个文本节点
1.创建文本节点
document.createTextNode();
2.规范化文本节点
使用normalize()方法,将空文本节点删除,将连续的两个文本节点合并
3.分割文本节点
使用splitText(),将一个文本节点分成两个文本节点,与normalize相反
Comment类型
DOM中的注释类型,与Text类型继承自相同的基类,因此它拥有除splitText()之外的所有字符串操作方法
可以通过nodeValue或data属性来获取注释的内容
CDATASection类型
只针对于XML的文档,表示的是CDATA区域
DocumentType类型
仅有firefox、Safari和Opera支持,包含着与文档的doctype相关的信息。没有子节点。
DocumentFragment类型
所有节点类型中,只有DocumentFragment在文档中没有对应的标记。
Attr类型
元素的特性在DOM中已Attr类型来表示。特性就是存在于attributes属性中的节点。
Attr有3个属性:name、value和specified(布尔值,用以区别特性是在代码中指定的,还是默认的)。
有下列方法(不常用):
createAttribute()、setAttributeNode()和getAttributeNode()

